- How to evaluate different algorithms in searching the text
- The most common use of the algorithms in text searching
(1) Searching Method:
- Search Sequentially
- Build Data structure to store the data
(2) Main Indexing Technique:
- inverted files
- suffix arrays
- signature files (popular in 1980s)
(3) Regular data structure using in information Retrieval
- sorted arrays
- binary search trees
- B-trees
- Hash table
- Tries
Inverted Files:
- Two elements: Vocabulary and occurrence
- Techniques: Block Addressing
Searching:
- Vocabulary Search
- Retrieval of Occurrence
- Manipulation of Occurrence
- Context inquires are complicated with inverted indices;
Construction:
- Building and maintaining an inverted index is relatively a low cost task
- All the data will be keep in a trie tree data structure
- Merging two indices include merging the sorted vocab
Other Indices for text:
Suffix Trees and Suffix Arrays:
- Suffix Arrays are a space efficient implementation of suffix trees
- Not all the text position needs to be indexed
Structure:
- Suffix Trees are built over all the suffix of the data
- Patricia Tree

Construction in Main Memory:
- concentrate on direct suffix construction

Construction on Suffix Arrays for Large Text:
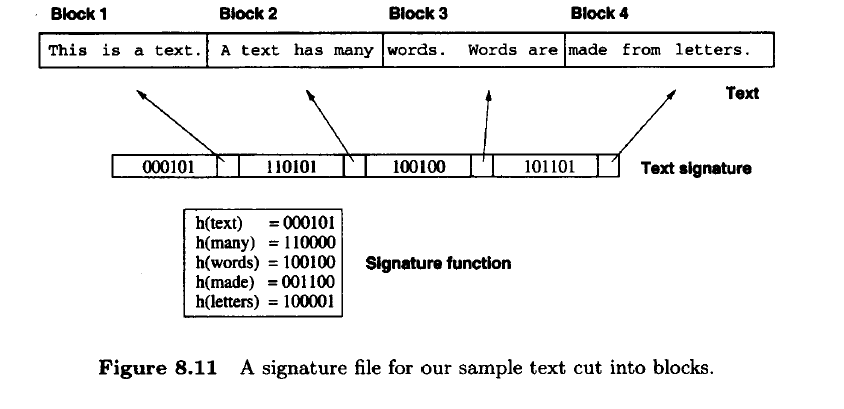
Signature Files:
Signature Files are word-oriented files based on hashing
Use hash functions to map words
Sequential Searching:
Search on the text that has no data structure to build on
Brute Force Method:
- Trying all possible text patterns
- Examine the Algor with the worst case
KMP Method:
- First linear with worst case behavior

Boyer-Moore Family:
Shift-Or
Suffix Automation:
Piratical Comparison:
Pattern Matching:

Regular Expression:

没有评论:
发表评论