1. Could you tell me more about how to use adaptive model in searching system?
2. How to get userProfile in the Adaptive system?
3. Could you tell me more about what kind of software they use in the collecting the data for the adaptive system?
2014年4月11日星期五
The text classification method: IIR 13,14,16,17
- Text classification and Naive Bayes:
A rule captures a certain combination of keywords that indicates a class.
Hand-coded rules have good scaling properties, but creating and maintaining
them over time is labor intensive.
Our goal in text classification is high accuracy on test data or new data – for example, the newswire articles that we will encounter tomorrow morning in the multicore chip example. It is easy to achieve high accuracy on the training set (e.g., we can simply memorize the labels). But high accuracy on the training set in general does not mean that the classifier will work well on new data in an application. When we use the training set to learn a classifier for test data, we make the assumption that training data and test data are similar or from the same distribution.
The Bernoulli model:
Properties of Naive Bayes
Even when assuming conditional independence, we still have too many parameters for the multinomial model if we assume a different probability distribution for each position k in the document. The position of a term in
a document by itself does not carry information about the class. Although there is a difference between China sues France and France sues China, the occurrence of China in position 1 versus position 3 of the document is not useful in NB classification because we look at each term separately. The conditional independence assumption commits us to this way of processing the evidence.
Vetor Space Classification:
The document representation in Naive Bayes is a sequence of terms or a binary vector 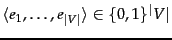 . In this chapter we adopt a different representation for text classification, the vector space model, developed . It represents each document as a vector with one real-valued component, usually a tf-idf weight, for each term. Thus, the document space
. In this chapter we adopt a different representation for text classification, the vector space model, developed . It represents each document as a vector with one real-valued component, usually a tf-idf weight, for each term. Thus, the document space 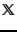 , the domain of the classification function
, the domain of the classification function 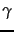 , is
, is 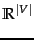 . This chapter introduces a number of classification methods that operate on real-valued vectors.
. This chapter introduces a number of classification methods that operate on real-valued vectors.
The basic hypothesis in using the vector space model for classification is the contiguity hypothesis .
Flat Clustering:
Clustering algorithms group a set of documents into subsets or clusters . The algorithms' goal is to create clusters that are coherent internally, but clearly different from each other. In other words, documents within a cluster should be as similar as possible; and documents in one cluster should be as dissimilar as possible from documents in other clusters.
![\includegraphics[width=4cm]{visualclusters.eps}](http://nlp.stanford.edu/IR-book/html/htmledition/img1387.png)
Clustering is the most common form of unsupervised learning . No supervision means that there is no human expert who has assigned documents to classes. In clustering, it is the distribution and makeup of the data that will determine cluster membership.
The difference between clustering and classification may not seem great at first. After all, in both cases we have a partition of a set of documents into groups. But as we will see the two problems are fundamentally different. Classification is a form of supervised learning: our goal is to replicate a categorical distinction that a human supervisor imposes on the data. In unsupervised learning, of which clustering is the most important example, we have no such teacher to guide us.
The key input to a clustering algorithm is the distance measure, the distance measure is distance in the 2D plane. This measure suggests three different clusters in the figure. In document clustering, the distance measure is often also Euclidean distance. Different distance measures give rise to different clusterings. Thus, the distance measure is an important means by which we can influence the outcome of clustering.
Flat clustering creates a flat set of clusters without any explicit structure that would relate clusters to each other. Hierarchical clustering creates a hierarchy of clusters and will be covered.
Hierarchical clustering
hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of clusters. Strategies for hierarchical clustering generally fall into two type:
- Agglomerative: This is a "bottom up" approach: each observation starts in its own cluster, and pairs of clusters are merged as one moves up the hierarchy.
- Divisive: This is a "top down" approach: all observations start in one cluster, and splits are performed recursively as one moves down the hierarchy.
In general, the merges and splits are determined in a greedy manner. The results of hierarchical clustering are usually presented in a dendrogram.
In the general case, the complexity of agglomerative clustering is  , which makes them too slow for large data sets. Divisive clustering with an exhaustive search is
, which makes them too slow for large data sets. Divisive clustering with an exhaustive search is  , which is even worse. However, for some special cases, optimal efficient agglomerative methods (of complexity
, which is even worse. However, for some special cases, optimal efficient agglomerative methods (of complexity 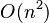 ) are known: SLINK[1] for single-linkage and CLINK[2] for complete-linkage clustering.
) are known: SLINK[1] for single-linkage and CLINK[2] for complete-linkage clustering.
, which makes them too slow for large data sets. Divisive clustering with an exhaustive search is , which is even worse. However, for some special cases, optimal efficient agglomerative methods (of complexity ) are known: SLINK[1] for single-linkage and CLINK[2] for complete-linkage clustering.2014年4月4日星期五
Muddiest Point
1. I still don't know how Map-Reduce system working ?
2. Why the parallel computing so popular? How google applies to it?
2. Why the parallel computing so popular? How google applies to it?
Personalized Web Exploration with Task Models
Personalized Web search emerged as one of the hottest topics for both the Web industry and academic researchers . Unlike traditional “one-size-fits-all” search engines, personalized search systems attempt to take into account interests, goals, and preferences of individual users in order to improve the relevance of search results and the overall retrieval experience. In the context of a tight competition between search engines and technologies, personalization is frequently considered as one of the technologies that can deliver a competitive advantage.
As long as the Web is getting closer and closer to becoming a primary source for all kinds of information, more and more users of Web search engines run exploratory searches to solve their
everyday needs. In addition, a growing proportion of users, such as information analysts, are engaged in Web based exploratory search professionally by the nature of their jobs. It makes exploratory Web
search both attractive and an important focus for research on search personalization. Yet, only a very small fraction of projects devoted to search personalization seek to support exploratory search.
The most typical usage of the profile is to rank information items. Filtering and recommendation systems simply rank the presented items by their similarity to the user profile. In personalized search systems, the profile is fused with the query and applied for filtering and re-ranking of initial search results. Referring to any specific paper is difficult, since there are dozens of reported systems using
this approach: see for a review.
TaskSieve was designed to assist users who perform exploratory searches reasonably often, i.e., it focuses on relatively experienced searchers up to the level of professional information analysts. These
users appreciate more powerful and sophisticated information access tools; but as we learned from our earlier work on adaptive filtering .
The flexibility in controlling the integration mode between queries and the task model also demonstrates its usefulness. First, we observed subjects switching among the different modes in their
searches. Second, the searches with the half-half mode produced the best results. Third, the searches in query-only mode produced better results than the baseline, which indicates that the users really
mastered the preset manipulations and used the appropriate mode for different searches. Finally, it is clear that none of the modes significantly dominates all the searches. All of these indicate that it
really makes sense for TaskSieve to let users decide the best mode for their searches.
As long as the Web is getting closer and closer to becoming a primary source for all kinds of information, more and more users of Web search engines run exploratory searches to solve their
everyday needs. In addition, a growing proportion of users, such as information analysts, are engaged in Web based exploratory search professionally by the nature of their jobs. It makes exploratory Web
search both attractive and an important focus for research on search personalization. Yet, only a very small fraction of projects devoted to search personalization seek to support exploratory search.
The most typical usage of the profile is to rank information items. Filtering and recommendation systems simply rank the presented items by their similarity to the user profile. In personalized search systems, the profile is fused with the query and applied for filtering and re-ranking of initial search results. Referring to any specific paper is difficult, since there are dozens of reported systems using
this approach: see for a review.
TaskSieve was designed to assist users who perform exploratory searches reasonably often, i.e., it focuses on relatively experienced searchers up to the level of professional information analysts. These
users appreciate more powerful and sophisticated information access tools; but as we learned from our earlier work on adaptive filtering .
The flexibility in controlling the integration mode between queries and the task model also demonstrates its usefulness. First, we observed subjects switching among the different modes in their
searches. Second, the searches with the half-half mode produced the best results. Third, the searches in query-only mode produced better results than the baseline, which indicates that the users really
mastered the preset manipulations and used the appropriate mode for different searches. Finally, it is clear that none of the modes significantly dominates all the searches. All of these indicate that it
really makes sense for TaskSieve to let users decide the best mode for their searches.
Content-based Recommender Systems: State of the Art and Trends
The abundance of information available on the Web and in Digital Libraries, in
combination with their dynamic and heterogeneous nature, has determined a rapidly
increasing difficulty in finding what we want when we need it and in a manner which
best meets our requirements.
A High Level Architecture of Content-based Systems
CONTENT ANALYZER – When information has no structure (e.g. text), some
kind of pre-processing step is needed to extract structured relevant information.
The main responsibility of the component is to represent the content of items
CONTENT ANALYZER – When information has no structure (e.g. text), some kind of pre-processing step is needed to extract structured relevant information.The main responsibility of the component is to represent the content of items(e.g. documents, Web pages, news, product descriptions, etc.) coming from information sources in a form suitable for the next processing steps. Data items are analyzed by feature extraction techniques in order to shift item representation from the original information space to the target one (e.g.Web pages represented as keyword vectors). This representation is the input to the PROFILE LEARNER and FILTERING COMPONENT;
Explicit feedback has the advantage of simplicity, albeit the adoption of numeric/symbolic scales increases the cognitive load on the user, and may not be adequate for catching user’s feeling about items. Implicit feedback methods arebased on assigning a relevance score to specific user actions on an item, such as saving, discarding, printing, bookmarking, etc. The main advantage is that they do
not require a direct user involvement, even though biasing is likely to occur, e.g.interruption of phone calls while reading.
Learning short-term and long-term profiles is quite typical of news filtering systems. NewsDude learns a short-term user model based on TF-IDF (cosine similarity), and a long-term model based on a na¨ıve Bayesian classifier by relying on an initial training set of interesting news articles provided by the user. The news source is Yahoo!News. In the same way Daily Learner, a learning agent for wireless information access, adopts an approach for learning two separate user-models. The former, based on a Nearest Neighbor text classification algorithm, maintains the short-term interests of users, while the latter, based on a na¨ıve Bayesian classifier, represents the long-term interests of users and relies on data collected over a longer period of time.
combination with their dynamic and heterogeneous nature, has determined a rapidly
increasing difficulty in finding what we want when we need it and in a manner which
best meets our requirements.
A High Level Architecture of Content-based Systems
CONTENT ANALYZER – When information has no structure (e.g. text), some
kind of pre-processing step is needed to extract structured relevant information.
The main responsibility of the component is to represent the content of items
CONTENT ANALYZER – When information has no structure (e.g. text), some kind of pre-processing step is needed to extract structured relevant information.The main responsibility of the component is to represent the content of items(e.g. documents, Web pages, news, product descriptions, etc.) coming from information sources in a form suitable for the next processing steps. Data items are analyzed by feature extraction techniques in order to shift item representation from the original information space to the target one (e.g.Web pages represented as keyword vectors). This representation is the input to the PROFILE LEARNER and FILTERING COMPONENT;
Explicit feedback has the advantage of simplicity, albeit the adoption of numeric/symbolic scales increases the cognitive load on the user, and may not be adequate for catching user’s feeling about items. Implicit feedback methods arebased on assigning a relevance score to specific user actions on an item, such as saving, discarding, printing, bookmarking, etc. The main advantage is that they do
not require a direct user involvement, even though biasing is likely to occur, e.g.interruption of phone calls while reading.
Learning short-term and long-term profiles is quite typical of news filtering systems. NewsDude learns a short-term user model based on TF-IDF (cosine similarity), and a long-term model based on a na¨ıve Bayesian classifier by relying on an initial training set of interesting news articles provided by the user. The news source is Yahoo!News. In the same way Daily Learner, a learning agent for wireless information access, adopts an approach for learning two separate user-models. The former, based on a Nearest Neighbor text classification algorithm, maintains the short-term interests of users, while the latter, based on a na¨ıve Bayesian classifier, represents the long-term interests of users and relies on data collected over a longer period of time.
User Profiles for Personalized Information Access
the user profiling process generally consists of three main phases. First, an information collection process is used to gather raw information about the user.
Collecting Information About Users:
There are five basic approaches to user identification: software agents, logins, enhanced proxy servers, cookies, and session ids.
This places no burden on the user at all. However, if the user uses more than one computer, each location will have a separate cookie, and thus a separate user profile. Also, if the computer is used by
more than one user, and all users share the same local user id, they will all share the
same, inaccurate profile.
Methods for User Information Collection
Commercial systems have been exploring customization for some time. Many
sites collect user preferences in order to customize interfaces. This customization can
be viewed as the first step to provide personalized services on the Web. Many of the
systems described in Section 2.4 rely on explicit user information. The collection of
preferences for each user can be seen as a user profile and the services provided by
these applications adapt in order to improve information accessibility. For instance,
MyYahoo! [110], explicitly ask the user to provide personal information that is stored
to create a profile. The Web site content is then automatically organized based on the
user’s preferences
Comparing Implicit and Explicit User Information Collection
Collecting Information About Users:
There are five basic approaches to user identification: software agents, logins, enhanced proxy servers, cookies, and session ids.
This places no burden on the user at all. However, if the user uses more than one computer, each location will have a separate cookie, and thus a separate user profile. Also, if the computer is used by
more than one user, and all users share the same local user id, they will all share the
same, inaccurate profile.
Methods for User Information Collection
Commercial systems have been exploring customization for some time. Many
sites collect user preferences in order to customize interfaces. This customization can
be viewed as the first step to provide personalized services on the Web. Many of the
systems described in Section 2.4 rely on explicit user information. The collection of
preferences for each user can be seen as a user profile and the services provided by
these applications adapt in order to improve information accessibility. For instance,
MyYahoo! [110], explicitly ask the user to provide personal information that is stored
to create a profile. The Web site content is then automatically organized based on the
user’s preferences
Comparing Implicit and Explicit User Information Collection
They found that the richer the amount of information available, the better the profile performed. In particular, they found that the user profile built from the user’s entire desktop index (the set of
all information created, copied, or viewed by the user) was most accurate, followed
by the profile built from recent information only, then that based on Web pages
only.
User Profile Construction:
The
profile is then refined as the user browses via a browsing agent and provides further
feedback on Web pages proposed by ifWeb. Keywords are extracted from each of the
pages receiving user feedback
2014年3月27日星期四
Cross Language Information Retrieval
1. Major Approaches and Challenges in CLIR
The mistakes of the translation
ambiguities exists in translation
Three major challenges in CLIR
1.what to translate
2. How to obtain translation knowledge
3.how to apply the translation knowledge
Identify the translation unit:
Three types of resources:
(1) bilingual dictionaries
(2) corpora focus
(3) word translation,phrase translation
Tokenization:
The process of recognizing words, Chinese characters will be more difficult
Stemming:
Three types of corpora, part of speech, tagging, syntactic parsing
To use bi-gram method and parse the words and use the decreasing order to rank and the highest point is recognized as the phrases.
Stop-words:
Obtaining Translation Knowledge:
Acquire the translation knowledge:
And extract the translation knowledge from translation resources
Obtain the bilingual resources dictionaries and corpora:
Extracting the translation knowledge:
Dealing with the out-of-corpors term:
Transliteration: Orthographic Mapping(Share the same alphabet order) and Phonetic Mapping.
Backoff Translation: (1) Match the surface form of the input terms (2) Match the stem form of the input terms (3)Using web mining to help to identify the words
pre_translation query expansion
Using Translation Knowledge:
Translation Disambiguation:
Weighting Translation Alternative:
IF_DF weighting
Cranfield Method Evaluation of the interactive system:
The mistakes of the translation
ambiguities exists in translation
Three major challenges in CLIR
1.what to translate
2. How to obtain translation knowledge
3.how to apply the translation knowledge
Identify the translation unit:
Three types of resources:
(1) bilingual dictionaries
(2) corpora focus
(3) word translation,phrase translation
Tokenization:
The process of recognizing words, Chinese characters will be more difficult
Stemming:
Three types of corpora, part of speech, tagging, syntactic parsing
To use bi-gram method and parse the words and use the decreasing order to rank and the highest point is recognized as the phrases.
Stop-words:
Obtaining Translation Knowledge:
Acquire the translation knowledge:
And extract the translation knowledge from translation resources
Obtain the bilingual resources dictionaries and corpora:
Extracting the translation knowledge:
Dealing with the out-of-corpors term:
Transliteration: Orthographic Mapping(Share the same alphabet order) and Phonetic Mapping.
Backoff Translation: (1) Match the surface form of the input terms (2) Match the stem form of the input terms (3)Using web mining to help to identify the words
pre_translation query expansion
Using Translation Knowledge:
Translation Disambiguation:
Weighting Translation Alternative:
IF_DF weighting
Cranfield Method Evaluation of the interactive system:
订阅:
博文 (Atom)