1. Could you tell me more about how to use adaptive model in searching system?
2. How to get userProfile in the Adaptive system?
3. Could you tell me more about what kind of software they use in the collecting the data for the adaptive system?
2014年4月11日星期五
The text classification method: IIR 13,14,16,17
- Text classification and Naive Bayes:
A rule captures a certain combination of keywords that indicates a class.
Hand-coded rules have good scaling properties, but creating and maintaining
them over time is labor intensive.
Our goal in text classification is high accuracy on test data or new data – for example, the newswire articles that we will encounter tomorrow morning in the multicore chip example. It is easy to achieve high accuracy on the training set (e.g., we can simply memorize the labels). But high accuracy on the training set in general does not mean that the classifier will work well on new data in an application. When we use the training set to learn a classifier for test data, we make the assumption that training data and test data are similar or from the same distribution.
The Bernoulli model:
Properties of Naive Bayes
Even when assuming conditional independence, we still have too many parameters for the multinomial model if we assume a different probability distribution for each position k in the document. The position of a term in
a document by itself does not carry information about the class. Although there is a difference between China sues France and France sues China, the occurrence of China in position 1 versus position 3 of the document is not useful in NB classification because we look at each term separately. The conditional independence assumption commits us to this way of processing the evidence.
Vetor Space Classification:
The document representation in Naive Bayes is a sequence of terms or a binary vector 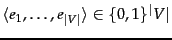 . In this chapter we adopt a different representation for text classification, the vector space model, developed . It represents each document as a vector with one real-valued component, usually a tf-idf weight, for each term. Thus, the document space
. In this chapter we adopt a different representation for text classification, the vector space model, developed . It represents each document as a vector with one real-valued component, usually a tf-idf weight, for each term. Thus, the document space 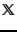 , the domain of the classification function
, the domain of the classification function 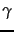 , is
, is 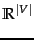 . This chapter introduces a number of classification methods that operate on real-valued vectors.
. This chapter introduces a number of classification methods that operate on real-valued vectors.
The basic hypothesis in using the vector space model for classification is the contiguity hypothesis .
Flat Clustering:
Clustering algorithms group a set of documents into subsets or clusters . The algorithms' goal is to create clusters that are coherent internally, but clearly different from each other. In other words, documents within a cluster should be as similar as possible; and documents in one cluster should be as dissimilar as possible from documents in other clusters.
![\includegraphics[width=4cm]{visualclusters.eps}](http://nlp.stanford.edu/IR-book/html/htmledition/img1387.png)
Clustering is the most common form of unsupervised learning . No supervision means that there is no human expert who has assigned documents to classes. In clustering, it is the distribution and makeup of the data that will determine cluster membership.
The difference between clustering and classification may not seem great at first. After all, in both cases we have a partition of a set of documents into groups. But as we will see the two problems are fundamentally different. Classification is a form of supervised learning: our goal is to replicate a categorical distinction that a human supervisor imposes on the data. In unsupervised learning, of which clustering is the most important example, we have no such teacher to guide us.
The key input to a clustering algorithm is the distance measure, the distance measure is distance in the 2D plane. This measure suggests three different clusters in the figure. In document clustering, the distance measure is often also Euclidean distance. Different distance measures give rise to different clusterings. Thus, the distance measure is an important means by which we can influence the outcome of clustering.
Flat clustering creates a flat set of clusters without any explicit structure that would relate clusters to each other. Hierarchical clustering creates a hierarchy of clusters and will be covered.
Hierarchical clustering
hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of clusters. Strategies for hierarchical clustering generally fall into two type:
- Agglomerative: This is a "bottom up" approach: each observation starts in its own cluster, and pairs of clusters are merged as one moves up the hierarchy.
- Divisive: This is a "top down" approach: all observations start in one cluster, and splits are performed recursively as one moves down the hierarchy.
In general, the merges and splits are determined in a greedy manner. The results of hierarchical clustering are usually presented in a dendrogram.
In the general case, the complexity of agglomerative clustering is  , which makes them too slow for large data sets. Divisive clustering with an exhaustive search is
, which makes them too slow for large data sets. Divisive clustering with an exhaustive search is  , which is even worse. However, for some special cases, optimal efficient agglomerative methods (of complexity
, which is even worse. However, for some special cases, optimal efficient agglomerative methods (of complexity  ) are known: SLINK[1] for single-linkage and CLINK[2] for complete-linkage clustering.
) are known: SLINK[1] for single-linkage and CLINK[2] for complete-linkage clustering.
, which makes them too slow for large data sets. Divisive clustering with an exhaustive search is , which is even worse. However, for some special cases, optimal efficient agglomerative methods (of complexity ) are known: SLINK[1] for single-linkage and CLINK[2] for complete-linkage clustering.2014年4月4日星期五
Muddiest Point
1. I still don't know how Map-Reduce system working ?
2. Why the parallel computing so popular? How google applies to it?
2. Why the parallel computing so popular? How google applies to it?
Personalized Web Exploration with Task Models
Personalized Web search emerged as one of the hottest topics for both the Web industry and academic researchers . Unlike traditional “one-size-fits-all” search engines, personalized search systems attempt to take into account interests, goals, and preferences of individual users in order to improve the relevance of search results and the overall retrieval experience. In the context of a tight competition between search engines and technologies, personalization is frequently considered as one of the technologies that can deliver a competitive advantage.
As long as the Web is getting closer and closer to becoming a primary source for all kinds of information, more and more users of Web search engines run exploratory searches to solve their
everyday needs. In addition, a growing proportion of users, such as information analysts, are engaged in Web based exploratory search professionally by the nature of their jobs. It makes exploratory Web
search both attractive and an important focus for research on search personalization. Yet, only a very small fraction of projects devoted to search personalization seek to support exploratory search.
The most typical usage of the profile is to rank information items. Filtering and recommendation systems simply rank the presented items by their similarity to the user profile. In personalized search systems, the profile is fused with the query and applied for filtering and re-ranking of initial search results. Referring to any specific paper is difficult, since there are dozens of reported systems using
this approach: see for a review.
TaskSieve was designed to assist users who perform exploratory searches reasonably often, i.e., it focuses on relatively experienced searchers up to the level of professional information analysts. These
users appreciate more powerful and sophisticated information access tools; but as we learned from our earlier work on adaptive filtering .
The flexibility in controlling the integration mode between queries and the task model also demonstrates its usefulness. First, we observed subjects switching among the different modes in their
searches. Second, the searches with the half-half mode produced the best results. Third, the searches in query-only mode produced better results than the baseline, which indicates that the users really
mastered the preset manipulations and used the appropriate mode for different searches. Finally, it is clear that none of the modes significantly dominates all the searches. All of these indicate that it
really makes sense for TaskSieve to let users decide the best mode for their searches.
As long as the Web is getting closer and closer to becoming a primary source for all kinds of information, more and more users of Web search engines run exploratory searches to solve their
everyday needs. In addition, a growing proportion of users, such as information analysts, are engaged in Web based exploratory search professionally by the nature of their jobs. It makes exploratory Web
search both attractive and an important focus for research on search personalization. Yet, only a very small fraction of projects devoted to search personalization seek to support exploratory search.
The most typical usage of the profile is to rank information items. Filtering and recommendation systems simply rank the presented items by their similarity to the user profile. In personalized search systems, the profile is fused with the query and applied for filtering and re-ranking of initial search results. Referring to any specific paper is difficult, since there are dozens of reported systems using
this approach: see for a review.
TaskSieve was designed to assist users who perform exploratory searches reasonably often, i.e., it focuses on relatively experienced searchers up to the level of professional information analysts. These
users appreciate more powerful and sophisticated information access tools; but as we learned from our earlier work on adaptive filtering .
The flexibility in controlling the integration mode between queries and the task model also demonstrates its usefulness. First, we observed subjects switching among the different modes in their
searches. Second, the searches with the half-half mode produced the best results. Third, the searches in query-only mode produced better results than the baseline, which indicates that the users really
mastered the preset manipulations and used the appropriate mode for different searches. Finally, it is clear that none of the modes significantly dominates all the searches. All of these indicate that it
really makes sense for TaskSieve to let users decide the best mode for their searches.
Content-based Recommender Systems: State of the Art and Trends
The abundance of information available on the Web and in Digital Libraries, in
combination with their dynamic and heterogeneous nature, has determined a rapidly
increasing difficulty in finding what we want when we need it and in a manner which
best meets our requirements.
A High Level Architecture of Content-based Systems
CONTENT ANALYZER – When information has no structure (e.g. text), some
kind of pre-processing step is needed to extract structured relevant information.
The main responsibility of the component is to represent the content of items
CONTENT ANALYZER – When information has no structure (e.g. text), some kind of pre-processing step is needed to extract structured relevant information.The main responsibility of the component is to represent the content of items(e.g. documents, Web pages, news, product descriptions, etc.) coming from information sources in a form suitable for the next processing steps. Data items are analyzed by feature extraction techniques in order to shift item representation from the original information space to the target one (e.g.Web pages represented as keyword vectors). This representation is the input to the PROFILE LEARNER and FILTERING COMPONENT;
Explicit feedback has the advantage of simplicity, albeit the adoption of numeric/symbolic scales increases the cognitive load on the user, and may not be adequate for catching user’s feeling about items. Implicit feedback methods arebased on assigning a relevance score to specific user actions on an item, such as saving, discarding, printing, bookmarking, etc. The main advantage is that they do
not require a direct user involvement, even though biasing is likely to occur, e.g.interruption of phone calls while reading.
Learning short-term and long-term profiles is quite typical of news filtering systems. NewsDude learns a short-term user model based on TF-IDF (cosine similarity), and a long-term model based on a na¨ıve Bayesian classifier by relying on an initial training set of interesting news articles provided by the user. The news source is Yahoo!News. In the same way Daily Learner, a learning agent for wireless information access, adopts an approach for learning two separate user-models. The former, based on a Nearest Neighbor text classification algorithm, maintains the short-term interests of users, while the latter, based on a na¨ıve Bayesian classifier, represents the long-term interests of users and relies on data collected over a longer period of time.
combination with their dynamic and heterogeneous nature, has determined a rapidly
increasing difficulty in finding what we want when we need it and in a manner which
best meets our requirements.
A High Level Architecture of Content-based Systems
CONTENT ANALYZER – When information has no structure (e.g. text), some
kind of pre-processing step is needed to extract structured relevant information.
The main responsibility of the component is to represent the content of items
CONTENT ANALYZER – When information has no structure (e.g. text), some kind of pre-processing step is needed to extract structured relevant information.The main responsibility of the component is to represent the content of items(e.g. documents, Web pages, news, product descriptions, etc.) coming from information sources in a form suitable for the next processing steps. Data items are analyzed by feature extraction techniques in order to shift item representation from the original information space to the target one (e.g.Web pages represented as keyword vectors). This representation is the input to the PROFILE LEARNER and FILTERING COMPONENT;
Explicit feedback has the advantage of simplicity, albeit the adoption of numeric/symbolic scales increases the cognitive load on the user, and may not be adequate for catching user’s feeling about items. Implicit feedback methods arebased on assigning a relevance score to specific user actions on an item, such as saving, discarding, printing, bookmarking, etc. The main advantage is that they do
not require a direct user involvement, even though biasing is likely to occur, e.g.interruption of phone calls while reading.
Learning short-term and long-term profiles is quite typical of news filtering systems. NewsDude learns a short-term user model based on TF-IDF (cosine similarity), and a long-term model based on a na¨ıve Bayesian classifier by relying on an initial training set of interesting news articles provided by the user. The news source is Yahoo!News. In the same way Daily Learner, a learning agent for wireless information access, adopts an approach for learning two separate user-models. The former, based on a Nearest Neighbor text classification algorithm, maintains the short-term interests of users, while the latter, based on a na¨ıve Bayesian classifier, represents the long-term interests of users and relies on data collected over a longer period of time.
User Profiles for Personalized Information Access
the user profiling process generally consists of three main phases. First, an information collection process is used to gather raw information about the user.
Collecting Information About Users:
There are five basic approaches to user identification: software agents, logins, enhanced proxy servers, cookies, and session ids.
This places no burden on the user at all. However, if the user uses more than one computer, each location will have a separate cookie, and thus a separate user profile. Also, if the computer is used by
more than one user, and all users share the same local user id, they will all share the
same, inaccurate profile.
Methods for User Information Collection
Commercial systems have been exploring customization for some time. Many
sites collect user preferences in order to customize interfaces. This customization can
be viewed as the first step to provide personalized services on the Web. Many of the
systems described in Section 2.4 rely on explicit user information. The collection of
preferences for each user can be seen as a user profile and the services provided by
these applications adapt in order to improve information accessibility. For instance,
MyYahoo! [110], explicitly ask the user to provide personal information that is stored
to create a profile. The Web site content is then automatically organized based on the
user’s preferences
Comparing Implicit and Explicit User Information Collection
Collecting Information About Users:
There are five basic approaches to user identification: software agents, logins, enhanced proxy servers, cookies, and session ids.
This places no burden on the user at all. However, if the user uses more than one computer, each location will have a separate cookie, and thus a separate user profile. Also, if the computer is used by
more than one user, and all users share the same local user id, they will all share the
same, inaccurate profile.
Methods for User Information Collection
Commercial systems have been exploring customization for some time. Many
sites collect user preferences in order to customize interfaces. This customization can
be viewed as the first step to provide personalized services on the Web. Many of the
systems described in Section 2.4 rely on explicit user information. The collection of
preferences for each user can be seen as a user profile and the services provided by
these applications adapt in order to improve information accessibility. For instance,
MyYahoo! [110], explicitly ask the user to provide personal information that is stored
to create a profile. The Web site content is then automatically organized based on the
user’s preferences
Comparing Implicit and Explicit User Information Collection
They found that the richer the amount of information available, the better the profile performed. In particular, they found that the user profile built from the user’s entire desktop index (the set of
all information created, copied, or viewed by the user) was most accurate, followed
by the profile built from recent information only, then that based on Web pages
only.
User Profile Construction:
The
profile is then refined as the user browses via a browsing agent and provides further
feedback on Web pages proposed by ifWeb. Keywords are extracted from each of the
pages receiving user feedback
2014年3月27日星期四
Cross Language Information Retrieval
1. Major Approaches and Challenges in CLIR
The mistakes of the translation
ambiguities exists in translation
Three major challenges in CLIR
1.what to translate
2. How to obtain translation knowledge
3.how to apply the translation knowledge
Identify the translation unit:
Three types of resources:
(1) bilingual dictionaries
(2) corpora focus
(3) word translation,phrase translation
Tokenization:
The process of recognizing words, Chinese characters will be more difficult
Stemming:
Three types of corpora, part of speech, tagging, syntactic parsing
To use bi-gram method and parse the words and use the decreasing order to rank and the highest point is recognized as the phrases.
Stop-words:
Obtaining Translation Knowledge:
Acquire the translation knowledge:
And extract the translation knowledge from translation resources
Obtain the bilingual resources dictionaries and corpora:
Extracting the translation knowledge:
Dealing with the out-of-corpors term:
Transliteration: Orthographic Mapping(Share the same alphabet order) and Phonetic Mapping.
Backoff Translation: (1) Match the surface form of the input terms (2) Match the stem form of the input terms (3)Using web mining to help to identify the words
pre_translation query expansion
Using Translation Knowledge:
Translation Disambiguation:
Weighting Translation Alternative:
IF_DF weighting
Cranfield Method Evaluation of the interactive system:
The mistakes of the translation
ambiguities exists in translation
Three major challenges in CLIR
1.what to translate
2. How to obtain translation knowledge
3.how to apply the translation knowledge
Identify the translation unit:
Three types of resources:
(1) bilingual dictionaries
(2) corpora focus
(3) word translation,phrase translation
Tokenization:
The process of recognizing words, Chinese characters will be more difficult
Stemming:
Three types of corpora, part of speech, tagging, syntactic parsing
To use bi-gram method and parse the words and use the decreasing order to rank and the highest point is recognized as the phrases.
Stop-words:
Obtaining Translation Knowledge:
Acquire the translation knowledge:
And extract the translation knowledge from translation resources
Obtain the bilingual resources dictionaries and corpora:
Extracting the translation knowledge:
Dealing with the out-of-corpors term:
Transliteration: Orthographic Mapping(Share the same alphabet order) and Phonetic Mapping.
Backoff Translation: (1) Match the surface form of the input terms (2) Match the stem form of the input terms (3)Using web mining to help to identify the words
pre_translation query expansion
Using Translation Knowledge:
Translation Disambiguation:
Weighting Translation Alternative:
IF_DF weighting
Cranfield Method Evaluation of the interactive system:
2014年3月26日星期三
Parallel Information Retrieval
1.Parallel Query Processing
2.parallel execution of off-line tasks
Parallel Query Processing:
index portioning;
replication;
Replication:
Treat the servers as nodes and create the replica of nodes, which will cause the n-fold increase in the service's engine rate. This is called the inter-query parallelism.
we could split the index into n parts and have each node work only on its own small part of the index. This approach is referred to as intra-query parallelism.
Two gauging indicators have been provided: engine service rate, average time per query;
Document partitioning:
Holds the subset of the documents;
The main advantage of the document-partitioned approach is its simplicity. Because all index
servers operate independently of each other, no additional complexity needs to be introduced
into the low-level query processing routines
How to divide the collection in the subsets of nodes:
By storing similar documents in the same node
Term Partitioning:
Holds the terms of the collections;
Term partitioning addresses the disk seek problem by splitting the collection into sets of terms
instead of sets of documents.
The scalability of the query:
As the collection becomes bigger, so do the individual postings lists. For a corpus composed of a billion documents, the postings list for a frequent term, such as “computer” or “internet”, can easily occupy several hundred megabytes.
Load Imbalance.
Term partitioning suffers from an uneven load across the index nodes.
Term-at-a-Time.
Perhaps the most severe limitation of the term-partitioned approach is its inability to support efficient document-at-a-time query processing
Hybrid Schemes:
Xi et al. (2002) propose a hybrid architecture in which the collection is divided into p subcollections according to a standard document partitioning scheme. The index for each subcollection is then term-partitioned across n/p nodes, so that each node in the system is responsible for all occurrences of a set of terms within one of the p subcollections.
Redundancy and Fault Tolerance:
Replication. We can maintain multiple copies of the same index node, as described in
the previous section on hybrid partitioning schemes.
Partial Replication. Instead of replicating the entire index r times, we may choose
to replicate index information only for important documents
Dormant Replication. Suppose the search engine comprises a total of n nodes. We can
divide the index found on each node vi into n − 1 fragments and distribute them evenly
among the n−1 remaining nodes, but leave them dormant (on disk) and not use them for
query processing.
Map-Reduce Framework:
Large Scale Data Processing: building and updating the index; identifying duplicate documents in the corpus; and analyzing the link structure of the document collection.
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
简单来说,一个映射函数就是对一些独立元素组成的概念上的列表(例如,一个测试成绩的列表)的每一个元素进行指定的操作(比如,有人发现所有学生的成绩都被高估了一分,他可以定义一个“减一”的映射函数,用来修正这个错误。)
In the map phase, key/value pairs are read from the input and the map function is
applied to each of them individually. The function is of the general form
map : (k, v) 7→ h (k1, v1), (k2, v2), . . . i. (14.9)
That is, for each key/value pair, map outputs a sequence of key/value pairs. This
sequence may or may not be empty, and the output keys may or may not be identical to
the input key (they usually aren’t).
• In the shuffle phase, the pairs produced during the map phase are sorted by their key,
and all values for the same key are grouped together.
• In the reduce phase, the reduce function is applied to each key and its values. The function
is of the form
reduce : (k, hv1, v2, . . .i) 7→ (k, hv′ 1, v′ 2, . . .i). (14.10)
Suppose we have a total of n = m + r machines, where m is the number of map workers and r is the number of reduce workers. The input of the MapReduce is broken into small pieces called map shards. Each shard typically holds between 16 and 64 MB of data. The shards are treated independently, and each shard is assigned to one of the m map workers. In a large MapReduce, it is common to have dozens or hundreds of map shards assigned to each map worker. A worker usually works on only 1 shard at a time, so all its shards have to be processed sequentially. However, if a worker has more than 1 CPU, it may improve performance to have it work on multiple shards in parallel.
2.parallel execution of off-line tasks
Parallel Query Processing:
index portioning;
replication;
Replication:
Treat the servers as nodes and create the replica of nodes, which will cause the n-fold increase in the service's engine rate. This is called the inter-query parallelism.
we could split the index into n parts and have each node work only on its own small part of the index. This approach is referred to as intra-query parallelism.
Two gauging indicators have been provided: engine service rate, average time per query;
Document partitioning:
Holds the subset of the documents;
The main advantage of the document-partitioned approach is its simplicity. Because all index
servers operate independently of each other, no additional complexity needs to be introduced
into the low-level query processing routines
How to divide the collection in the subsets of nodes:
By storing similar documents in the same node
Term Partitioning:
Holds the terms of the collections;
Term partitioning addresses the disk seek problem by splitting the collection into sets of terms
instead of sets of documents.
The scalability of the query:
As the collection becomes bigger, so do the individual postings lists. For a corpus composed of a billion documents, the postings list for a frequent term, such as “computer” or “internet”, can easily occupy several hundred megabytes.
Load Imbalance.
Term partitioning suffers from an uneven load across the index nodes.
Term-at-a-Time.
Perhaps the most severe limitation of the term-partitioned approach is its inability to support efficient document-at-a-time query processing
Hybrid Schemes:
Xi et al. (2002) propose a hybrid architecture in which the collection is divided into p subcollections according to a standard document partitioning scheme. The index for each subcollection is then term-partitioned across n/p nodes, so that each node in the system is responsible for all occurrences of a set of terms within one of the p subcollections.
Redundancy and Fault Tolerance:
Replication. We can maintain multiple copies of the same index node, as described in
the previous section on hybrid partitioning schemes.
Partial Replication. Instead of replicating the entire index r times, we may choose
to replicate index information only for important documents
Dormant Replication. Suppose the search engine comprises a total of n nodes. We can
divide the index found on each node vi into n − 1 fragments and distribute them evenly
among the n−1 remaining nodes, but leave them dormant (on disk) and not use them for
query processing.
Map-Reduce Framework:
Large Scale Data Processing: building and updating the index; identifying duplicate documents in the corpus; and analyzing the link structure of the document collection.
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
简单来说,一个映射函数就是对一些独立元素组成的概念上的列表(例如,一个测试成绩的列表)的每一个元素进行指定的操作(比如,有人发现所有学生的成绩都被高估了一分,他可以定义一个“减一”的映射函数,用来修正这个错误。)
In the map phase, key/value pairs are read from the input and the map function is
applied to each of them individually. The function is of the general form
map : (k, v) 7→ h (k1, v1), (k2, v2), . . . i. (14.9)
That is, for each key/value pair, map outputs a sequence of key/value pairs. This
sequence may or may not be empty, and the output keys may or may not be identical to
the input key (they usually aren’t).
• In the shuffle phase, the pairs produced during the map phase are sorted by their key,
and all values for the same key are grouped together.
• In the reduce phase, the reduce function is applied to each key and its values. The function
is of the form
reduce : (k, hv1, v2, . . .i) 7→ (k, hv′ 1, v′ 2, . . .i). (14.10)
Suppose we have a total of n = m + r machines, where m is the number of map workers and r is the number of reduce workers. The input of the MapReduce is broken into small pieces called map shards. Each shard typically holds between 16 and 64 MB of data. The shards are treated independently, and each shard is assigned to one of the m map workers. In a large MapReduce, it is common to have dozens or hundreds of map shards assigned to each map worker. A worker usually works on only 1 shard at a time, so all its shards have to be processed sequentially. However, if a worker has more than 1 CPU, it may improve performance to have it work on multiple shards in parallel.
map()函数以key/value对作为输入,产生另外一系列key/value对作为中间输出写入本地磁盘。MapReduce框架会自动将这些中间数据按照key值进行聚集,且key值相同(用户可设定聚集策略,默认情况下是对key值进行哈希取模)的数据被统一交给reduce()函数处理。
reduce()函数以key及对应的value列表作为输入,经合并key相同的value值后,产生另外一系列key/value对作为最终输出写入HDFS。
下面以MapReduce中的“hello world”程序—WordCount为例介绍程序设计方法。
“hello world”程序是我们学习任何一门编程语言编写的第一个程序。它简单且易于理解,能够帮助读者快速入门。同样,分布式处理框架也有自己的“hello world”程序:WordCount。它完成的功能是统计输入文件中的每个单词出现的次数。在MapReduce中,可以这样编写(伪代码)。
2014年3月25日星期二
Multilingual Information Access
This essay is mainly talked about the Multi-language models called cross language retrieval model.
This model is to help the user to improve their cross language search in the text.
There are benefits for polygots:
language. Polyglots can benefit from MLIA in at least three ways: (1) they can find documents in more than one language with a single search, (2) they can formulate queries in the language(s) for which their active vocabulary is largest, and (3) they can move more seamlessly across languages over the
course of an information seeking episode than would be possible if documents written in
different languages were available only from different information systems.
Background for people why they want to do the multi-language searching:
1. The cold war background
2. The world war two
3. The world wide web (The emergence)
4. IBM: The machine can learn to translate by statistical analysis.
Cross Language information retrieval:
(1) language and character set identification, (2) language-specific processing, and (3) construction of an “inverted index” that allows rapid identification of which documents contain specific terms. Sometimes the language in which a document is written and the character set used to encode it can be inferred from its source (e.g.., New York Times articles are almost always written in English, and typically encoded in ASCII) and sometimes the language and character set might be indicated using metadata (e.g., the HTML standard used for Web pages provides metadata fields for these purposes).
The distinguishing technique for the Cross Language Information Retrieval:
(1) translate each term using the context in which that word appears to help select the right translation, (2) count the terms and then translate the aggregate counts without regard to the context of individual occurrences, or (3) compute some more sophisticated aggregate “term weight” for each term, and then translate those weights.
The Problems still exists in the Cross language search:
1. The egg or the basket problem
2. Present ranking problem
3. The similar drives for the development of the new search engine
This model is to help the user to improve their cross language search in the text.
There are benefits for polygots:
language. Polyglots can benefit from MLIA in at least three ways: (1) they can find documents in more than one language with a single search, (2) they can formulate queries in the language(s) for which their active vocabulary is largest, and (3) they can move more seamlessly across languages over the
course of an information seeking episode than would be possible if documents written in
different languages were available only from different information systems.
Background for people why they want to do the multi-language searching:
1. The cold war background
2. The world war two
3. The world wide web (The emergence)
4. IBM: The machine can learn to translate by statistical analysis.
Cross Language information retrieval:
(1) language and character set identification, (2) language-specific processing, and (3) construction of an “inverted index” that allows rapid identification of which documents contain specific terms. Sometimes the language in which a document is written and the character set used to encode it can be inferred from its source (e.g.., New York Times articles are almost always written in English, and typically encoded in ASCII) and sometimes the language and character set might be indicated using metadata (e.g., the HTML standard used for Web pages provides metadata fields for these purposes).
The distinguishing technique for the Cross Language Information Retrieval:
(1) translate each term using the context in which that word appears to help select the right translation, (2) count the terms and then translate the aggregate counts without regard to the context of individual occurrences, or (3) compute some more sophisticated aggregate “term weight” for each term, and then translate those weights.
The Problems still exists in the Cross language search:
1. The egg or the basket problem
2. Present ranking problem
3. The similar drives for the development of the new search engine
Muddies Point
1. I still don't quite understand why Page Rank works ? What is the difference between the Page Rank and the HITS model? Could you explain more to me?
2. Could you introduce us some of the useful crawler we can use grab the text from internet? I think it will be very useful if you provide some
2. Could you introduce us some of the useful crawler we can use grab the text from internet? I think it will be very useful if you provide some
2014年3月18日星期二
The anatomy of large-scale hyper textual web search engine
How to build the effective search engine as Google in case study.
The scaling web engine:
The WWWW , has been indexing over 110,000 web pages;
The main components for building a effective search engine:
(1) The faster crawler
(2) The large storage
(3) The queries must be handled fastly
(4) and also the fast indexing system
The another problem:
The web pages are expanding but the people viewing the results are not changed.
The google best practice:
(1) Page Rank (2) And using the link to improve the search results
Page Rank Calculation:
The assumption:
The user just randomly choose the webpage and never hits back but later on he has to start again.
The random probability that the surfer will browse the page is the PAGE RANK.
And the dampen factor is that the surfer will be easily get board and will start all over again.
We assume page A has pages T1...Tn which point to it (i.e., are citations). The parameter d
is a damping factor which can be set between 0 and 1. We usually set d to 0.85. There are
more details about d in the next section. Also C(A) is defined as the number of links going
out of page A. The PageRank of a page A is given as follows:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
Note that the PageRanks form a probability distribution over web pages, so the sum of all
web pages’ PageRanks will be one
The google Architecture overview:
The scaling web engine:
The WWWW , has been indexing over 110,000 web pages;
The main components for building a effective search engine:
(1) The faster crawler
(2) The large storage
(3) The queries must be handled fastly
(4) and also the fast indexing system
The another problem:
The web pages are expanding but the people viewing the results are not changed.
The google best practice:
(1) Page Rank (2) And using the link to improve the search results
Page Rank Calculation:
The assumption:
The user just randomly choose the webpage and never hits back but later on he has to start again.
The random probability that the surfer will browse the page is the PAGE RANK.
And the dampen factor is that the surfer will be easily get board and will start all over again.
We assume page A has pages T1...Tn which point to it (i.e., are citations). The parameter d
is a damping factor which can be set between 0 and 1. We usually set d to 0.85. There are
more details about d in the next section. Also C(A) is defined as the number of links going
out of page A. The PageRank of a page A is given as follows:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
Note that the PageRanks form a probability distribution over web pages, so the sum of all
web pages’ PageRanks will be one
The google Architecture overview:
Authoritative Sources in a hyperlink environment
This paper is mainly focused on extract information from the linked structure and gauging their effectiveness.
The procedure of searching:
user-supplied query:
specific query; It has scarcity problem which means it has fewer pages
board topics query; It needs the way to filter
similar page query:
There are two difficulties for the search of authorities:
1. There are millions similar words for Harvard
2., The search engine problem
Analysis of the linked structured:
Construct the algor that contains the most of this topics;
There is problem in relevance and popularity, they build the algor to test the whether this website is the hub.
The goal for this paper:
Our approach to discovering authoritative www sources is meant to have a global nature: We wish to identify the most central pages for broad search topics in the context of the www as a whole.
Section 2: subgraph for building the relevant topics
Section 3& 4: algorithm for identifying the hubs in a subgraph
The paper uses the graph algorithm to test whether the central pages can be the hub of all the webstie
The procedure of searching:
user-supplied query:
specific query; It has scarcity problem which means it has fewer pages
board topics query; It needs the way to filter
similar page query:
There are two difficulties for the search of authorities:
1. There are millions similar words for Harvard
2., The search engine problem
Analysis of the linked structured:
Construct the algor that contains the most of this topics;
There is problem in relevance and popularity, they build the algor to test the whether this website is the hub.
The goal for this paper:
Our approach to discovering authoritative www sources is meant to have a global nature: We wish to identify the most central pages for broad search topics in the context of the www as a whole.
Section 2: subgraph for building the relevant topics
Section 3& 4: algorithm for identifying the hubs in a subgraph
The paper uses the graph algorithm to test whether the central pages can be the hub of all the webstie
2014年3月17日星期一
MIR Chapter 13
Three different forms of searching the web:
(1) search engine, the full text database
(2) Search the web by subjects
The outline
(1) Statistics problem
(2) main tools we do the search today
Challenges:
First Class: Data
(1) Distributed Data
(2) High percentage of volatile of data( it means there are a lot of adding and deleting in data links of data)
(3) Large Volume
(4) redundant data: highly unstructured for the web
(5) The quality of data would be judged and sometimes it is low quality
Conclusion: The quality of data will not changed
Second Class: Interaction with data problem
(1)how to specify the query
(2) how to interpret the answer by the query
Modeling the web:
The character of the web: The vocab grows faster and the word distribution should be more biased.


(1) search engine, the full text database
(2) Search the web by subjects
The outline
(1) Statistics problem
(2) main tools we do the search today
Challenges:
First Class: Data
(1) Distributed Data
(2) High percentage of volatile of data( it means there are a lot of adding and deleting in data links of data)
(3) Large Volume
(4) redundant data: highly unstructured for the web
(5) The quality of data would be judged and sometimes it is low quality
Conclusion: The quality of data will not changed
Second Class: Interaction with data problem
(1)how to specify the query
(2) how to interpret the answer by the query
Modeling the web:
The character of the web: The vocab grows faster and the word distribution should be more biased.
the file sizes are in the middle which is similar to normal distribution, but it has a different right tail distribution of different file types.
Search Engines:
centralized crawler-indexer architecture
crawler built the indexer, query engine built the index
The problem with the crawler: can not cope with high volume of data
Distributed Architecture:
The harvest distributed:
Gathers and brokers:
Gathers: are collecting and indexing different information from one web to another.
Broker: provide the indexing mechanism
One of the goals of Harvest is to build topic-specific brokers, focusing the
index contents and avoiding many of the vocabulary and scaling problems of
generic indices.
User Interface:
The query interface, answer interface
Ranking:
The usual ranking algorithm can not be opened to others.
The improvement:
(1 ) Vector spread, boolean spread
(2) page rank algorithm ( taken into the link and pointers into consideration)
The first assumption: PageRank simulates a user navigating randomly in the Web who jumps to a random page with probability q or follows a random hyperlink (on the current page) with probability 1 - q.
The second assumption: It is further assumed that this user never goes back to a previously visited page following an already traversed hyperlink backwards. This process can be modeled with a Markov chain, from the stationary probability of being in each page can be computed.
Hypertext Induced Topic Search:
Pages that have many links pointing to them in S are called authorities (that is, they should have relevant content). Pages that have many outgoing links are called hubs (they should point to similar content).
如果文档有相似的内容(就是一个网页有很多内容指向一个页面), 如果一个网页有很多外联的网页,那就叫做hub.
Crawling the web:
The simplest is to start with a set of URLs and from there extract other URLs which are followed recursively in a breadth-first or depth-first fashion.
2014年2月28日星期五
Muddiest Point:
1. In designing the search interface, how many factors should be taken into consideration?
2. Could you show me some classic user interface design to me and explain why they are so popular?
3. What is the best source for user interface design?
4. How human factors involve in interface design and which is more important?
2. Could you show me some classic user interface design to me and explain why they are so popular?
3. What is the best source for user interface design?
4. How human factors involve in interface design and which is more important?
Chapter 10: User Interface Visualization
Main: This Chapter will mainly outline the process of the user information;
Human Computer Interaction:
Design Principals:
1. User Feedbacks
2. Reduce Working Memory Load
3. Provide Interface for Alternative Users
The role of visualization:
Difficult: To make abstract inherent idea becoming blatantly
Evaluating Interactive System:
The technique for visualization:
1. Brushing and linking
Meaning: Connecting two or more views of the same data the titles and histograms
2.panning and zooming
Move back and forth to the same view
3. focused plus contexts
4.magic lenses
The process of the visualization:
Form the idea, generate the query, and return the results on whether it stops or continue
Non-search part of the information Process:
The Four main Starting points for the user interfaces:
Lists of Collection:
Display Hierarchies
Example: Yahoo, and HB System
Automatically Derived Collection Overview:
Evaluation of Graphical Overview:
Co-citation Clustering for overviews:
Examples Dialog and Wizards:
Automated Source Selection:
Generating the Queries:
1. Boolean Queries
2. Faceted Queries
3. Graphical Approach for Queries
4. Phrase and Proximity
5. Natural Language and Language Processing
Human Computer Interaction:
Design Principals:
1. User Feedbacks
2. Reduce Working Memory Load
3. Provide Interface for Alternative Users
The role of visualization:
Difficult: To make abstract inherent idea becoming blatantly
Evaluating Interactive System:
The technique for visualization:
1. Brushing and linking
Meaning: Connecting two or more views of the same data the titles and histograms
2.panning and zooming
Move back and forth to the same view
3. focused plus contexts
4.magic lenses
The process of the visualization:
Form the idea, generate the query, and return the results on whether it stops or continue
Non-search part of the information Process:
The Four main Starting points for the user interfaces:
Lists of Collection:
Display Hierarchies
Example: Yahoo, and HB System
Automatically Derived Collection Overview:
Evaluation of Graphical Overview:
Co-citation Clustering for overviews:
Examples Dialog and Wizards:
Automated Source Selection:
Generating the Queries:
1. Boolean Queries
2. Faceted Queries
3. Graphical Approach for Queries
4. Phrase and Proximity
5. Natural Language and Language Processing
Visualization for Text Analysis
This chapter describes ideas that have been put forward for understanding the contents of text collections from a more analytical point of view.
Visualization for text mining:
1.TAKMI Text Mining System
2.Jigsaw system (Gorg et al., 2007) was designed to allow intelligence analysts to examine relationships among entities mentioned in a document collection and phone logs.
3.The BETA system, part of the IBM Web Fountain project (Meredith and Pieper, 2006), also had the goal of facilitating exploration of data within dimensions automatically extracted from text.
4. The TRIST information “triage” system (Jonker et al., 2005, Proulx et al., 2006) attempted to address many of the deficiencies of standard search for information analysts' tasks.
1.2 The work Frequency of the visualization
1.The SeeSoft visualization (Eick, 1994) represented text in a manner resembling columns of newspaper text, with one “line” of text on each horizontal line of the strip
2. The TextArc visualization (Paley, 2002) is similar to SeeSoft, but arranged the lines of text in a spiral and placed frequently occurring words within the center of the spiral.
1.3 Visualization And relationship
Some more recent approaches have moved away from nodes-and-links in order to break the interesting relationships into pieces and show their connections via brushing-and-linking interactions.
Visualization for text mining:
1.TAKMI Text Mining System
2.Jigsaw system (Gorg et al., 2007) was designed to allow intelligence analysts to examine relationships among entities mentioned in a document collection and phone logs.
3.The BETA system, part of the IBM Web Fountain project (Meredith and Pieper, 2006), also had the goal of facilitating exploration of data within dimensions automatically extracted from text.
4. The TRIST information “triage” system (Jonker et al., 2005, Proulx et al., 2006) attempted to address many of the deficiencies of standard search for information analysts' tasks.
1.2 The work Frequency of the visualization
1.The SeeSoft visualization (Eick, 1994) represented text in a manner resembling columns of newspaper text, with one “line” of text on each horizontal line of the strip
2. The TextArc visualization (Paley, 2002) is similar to SeeSoft, but arranged the lines of text in a spiral and placed frequently occurring words within the center of the spiral.
1.3 Visualization And relationship
Some more recent approaches have moved away from nodes-and-links in order to break the interesting relationships into pieces and show their connections via brushing-and-linking interactions.
THE DESIGN OF SEARCH USER INTERFACES
1.1 Keeping the User Interface Simple
1. Do not want to be interrupted
2. Focused is the intensive task
3. Be fitted to all ages
1.2 The historical Shift in the design of the interface
1.3 The process of the interface design
- Learnability: How easy is it for users to accomplish basic tasks the first time they encounter the interface?
- Efficiency: How quickly can users accomplish their tasks after they learn how to use the interface?
- Memorability: After a period of non-use, how long does it take users to reestablish proficiency?
- Errors: How many errors do users make, how severe are these errors, and how easy is it for users to recover from these errors?
- Satisfaction: How pleasant or satisfying is it to use the interface
After a design is testing well in discount or informal studies, formal experiments comparing different designs and measuring for statistically significant differences can be conducted.
1.4 The guidelines for the Design
- Offer informative feedback.
- Support user control.
- Reduce short-term memory load.
- Provide shortcuts for skilled users.
- Reduce errors; offer simple error handling.
- Strive for consistency.
- Permit easy reversal of actions.
- Design for closure.
1.5 Offer Efficient and Informative Feedback
Show Search Result Immediately
Show Informative Documents immediately
Allow Sorting of Results By Criteria
Show Query Term Suggestions
Use Relevant Indicators Sparsely
Support Rapid Response
- Offer efficient and informative feedback,
- Balance user control with automated actions,
- Reduce short-term memory load,
- Provide shortcuts,
- Reduce errors,
- Recognize the importance of small details, and
- Recognize the importance of aesthetics.
2014年2月21日星期五
Muddiest Point
I am still confused about the cranfield method and could you please provide more examples on that?
What is the main strategies for global and local method in doing relevance feed back?
What is the main strategies for global and local method in doing relevance feed back?
Chapter 9: relevance feedback and query expansion
Global Techniques: Global methods are techniques for expanding or reformulating query terms independent of the query and results returned from it, so that changes in the query wording will cause the new query to match other semantically similar terms.
Local Techniques: Local methods adjust a query relative to the documents that initially appear
to match the query
The Rocchio algorithm for relevance feedback
The underlying theory.
An application of Rocchio’s algorithm. Some documents have been labeled as relevant and nonrelevant and the initial query vector ismoved in response to this feedback.
Probabilistic relevance feedback
Rather than reweighting the query in a vector space, if a user has told us some relevant and nonrelevant documents, then we can proceed to build a classifier. One way of doing this is with a Naive Bayes probabilistic model.
Misspellings. If the user spells a term in a different way to the way it is spelled in any document in the collection, then relevance feedback is unlikely to be effective.
Cross-language information retrieval. Documents in another language are not nearby in a vector space based on term distribution. Rather, documents in the same language cluster more closely together.
Mismatch of searcher’s vocabulary versus collection vocabulary. If the user searches for laptop but all the documents use the term notebook computer, then the query will fail, and relevance feedback is again most likely ineffective.
Relevance feedback on the web
Local Techniques: Local methods adjust a query relative to the documents that initially appear
to match the query
The Rocchio algorithm for relevance feedback
The underlying theory.
An application of Rocchio’s algorithm. Some documents have been labeled as relevant and nonrelevant and the initial query vector ismoved in response to this feedback.
Probabilistic relevance feedback
Rather than reweighting the query in a vector space, if a user has told us some relevant and nonrelevant documents, then we can proceed to build a classifier. One way of doing this is with a Naive Bayes probabilistic model.
Misspellings. If the user spells a term in a different way to the way it is spelled in any document in the collection, then relevance feedback is unlikely to be effective.
Cross-language information retrieval. Documents in another language are not nearby in a vector space based on term distribution. Rather, documents in the same language cluster more closely together.
Mismatch of searcher’s vocabulary versus collection vocabulary. If the user searches for laptop but all the documents use the term notebook computer, then the query will fail, and relevance feedback is again most likely ineffective.
Relevance feedback on the web
Relevance feedback has been shown to be very effective at improving relevance of results. Its successful use requires queries for which the set of relevant documents is medium to large. Full relevance feedback is often onerous for the user, and its implementation is not very efficient in most IR systems.In many cases, other types of interactive retrievalmay improve relevance by about as much with less work.
Relevance Feedback Revisited
Cranfield Method
1400 documents
The vector space model uses all terms in rerneved relevant documents for query expansion, but Harrnan (1988) showed that adding only selected terms from retrieved relevant
documents was more effective than adding all the terms, at least for the one test collection used (Cranfield 1400).
The past study if relevance feedback:
The Vector Space Model

Croft and Harper (1979) extended this weighting scheme by suggesting effective initial search methods based on showing that the weighting scheme reduced to IDF weighting when no documents have been seen (the initial search). In 1983 Croft further extended the probabilistic weighting by adapting the
probabilistic model to handle within document frequency weights.
Query Expansion:
Since the sorting techniques used have a major effect on performance using query expansion, four new sorting techniques were investigated. Unlike the earlier techniques which were based on products of factors known to be important in selecting terms (such as the total frequency of a term in the
relevant subset, the IDF of a term, etc.), these new sorts were all related to ratios or probabilities of terms occurring in relevant documents vs occurring in non-relevant documents.
Relevance Feedback in Multiple Iterations:
Threemajor recommendations can be made from sutnmsrizing the results from term weighting and query expansion using a probabilistic model.
1400 documents
The vector space model uses all terms in rerneved relevant documents for query expansion, but Harrnan (1988) showed that adding only selected terms from retrieved relevant
documents was more effective than adding all the terms, at least for the one test collection used (Cranfield 1400).
The past study if relevance feedback:
The Vector Space Model
The Probabilistic Model
probabilistic model to handle within document frequency weights.
Query Expansion:
Since the sorting techniques used have a major effect on performance using query expansion, four new sorting techniques were investigated. Unlike the earlier techniques which were based on products of factors known to be important in selecting terms (such as the total frequency of a term in the
relevant subset, the IDF of a term, etc.), these new sorts were all related to ratios or probabilities of terms occurring in relevant documents vs occurring in non-relevant documents.
Relevance Feedback in Multiple Iterations:
Threemajor recommendations can be made from sutnmsrizing the results from term weighting and query expansion using a probabilistic model.
A Study of Methods for Negative Relevance Feedback
Topic: Exploring the techniques of improving the different negative feedback
Proposed of the question:
Given a query Q and a document collection C, a retrieval system returns a ranked list of documents L. Li denotes the i-th ranked document in the ranked list. We assume that Q is so dif ficult that all the top f ranked documents (seen so far by a user) are non-relevant. The goal is to study how to use these negative examples, i.e., N = fL1; :::; Lf g, to rerank the next r unseen documents in the original ranked list: U = fLf+1; :::; Lf+rg. We set f = 10 to simulate that the rst page of search results are irrelevant,
and set r = 1000.
Score combination:

Q is query, D is document, when beta equals 0, it does not perform any negative feedback, but when beta is equals to negative, they will penalize the data.
Two methods to be:
Local Method: Rank all the documents in U by the negative query and penalize the top p documents.
Global Method: Rank all the documents in C by the negative query. Select, from the top p documents of this ranked list, those documents in U to penalize.

Proposed of the question:
Given a query Q and a document collection C, a retrieval system returns a ranked list of documents L. Li denotes the i-th ranked document in the ranked list. We assume that Q is so dif ficult that all the top f ranked documents (seen so far by a user) are non-relevant. The goal is to study how to use these negative examples, i.e., N = fL1; :::; Lf g, to rerank the next r unseen documents in the original ranked list: U = fLf+1; :::; Lf+rg. We set f = 10 to simulate that the rst page of search results are irrelevant,
and set r = 1000.
Score combination:
Q is query, D is document, when beta equals 0, it does not perform any negative feedback, but when beta is equals to negative, they will penalize the data.
Two methods to be:
Local Method: Rank all the documents in U by the negative query and penalize the top p documents.
Global Method: Rank all the documents in C by the negative query. Select, from the top p documents of this ranked list, those documents in U to penalize.
VECTOR SPACE MODEL
conclusions:
Negative feedback is very important because it can help a user when search results are very poor.
This work inspires several future directions. First, we can study a more principled way to model multiple negative models and use these multiple negative models to conduct constrained query expansion, for example, avoiding terms which are in negative models. Second, we are interested in a learning framework which can utilize both a little positive information (original queries) and a certain amount of negative information to learn a ranking function to help dif fcult queries. Third, queries are dif cult due to different reasons. Identifying these reasons and customizing negative feedback
strategies would be much worth studying.
2014年2月18日星期二
Notes: Improving the effectiveness of information retrieval with local context analysis
Problem: the automatic expansion for the queries, which is better: the global or local method
Technique for automatic expansion:
1. term clustering
2. local: documents based on the top ranked retrieved from the query
Effect: the local feedback can improve the retrieved results
3. new method: local context analysis: concurrences analysis techniques
use the top-ranked documents for expansion
Global Techniques:
1. term clustering: group the terms based on their concurrence
problem: it can not solve the ambiguous terms
2. Dimensional Reduction:
3. Phrasefinder: so far the most successful skills,
Local Techniques:
1. local feedback
2. Local context analysis:
The most critical function of a local feedback algorithm is to separate terms in the top-ranked relevant documents from those in top-ranked nonrelevant documents.
The most frequent terms (except stopwords) in the top-ranked documents are used for query expansion.
HYPOTHESIS. A common term from the top-ranked relevant documents will tend to cooccur with all query terms within the top-ranked documents.
Method:
1. Build Concurrence Metrics
2. Combining the degrees of cooccurrence with all query terms
3. Differentiating rare and common query terms
problems [Ponte 1998].
In summary, local context analysis takes these steps to expand a query Q on a collection C:
(1) Perform an initial retrieval on C to get the top-ranked set S for Q.
(2) Rank the concepts in the top-ranked set using the formula f~c, Q!.
(3) Add the best k concepts to Q.
Figure 1 shows an example query expanded by local context analysis
The application for the local context analysis:
1. The cross language retrieval
2. The topic segmentation
3. Distribution of IR, choosing the right collections to search for
The experimental conclusion:
Technique for automatic expansion:
1. term clustering
2. local: documents based on the top ranked retrieved from the query
Effect: the local feedback can improve the retrieved results
3. new method: local context analysis: concurrences analysis techniques
use the top-ranked documents for expansion
Global Techniques:
1. term clustering: group the terms based on their concurrence
problem: it can not solve the ambiguous terms
2. Dimensional Reduction:
3. Phrasefinder: so far the most successful skills,
Local Techniques:
1. local feedback
2. Local context analysis:
The most critical function of a local feedback algorithm is to separate terms in the top-ranked relevant documents from those in top-ranked nonrelevant documents.
The most frequent terms (except stopwords) in the top-ranked documents are used for query expansion.
HYPOTHESIS. A common term from the top-ranked relevant documents will tend to cooccur with all query terms within the top-ranked documents.
Method:
1. Build Concurrence Metrics
2. Combining the degrees of cooccurrence with all query terms
3. Differentiating rare and common query terms
problems [Ponte 1998].
In summary, local context analysis takes these steps to expand a query Q on a collection C:
(1) Perform an initial retrieval on C to get the top-ranked set S for Q.
(2) Rank the concepts in the top-ranked set using the formula f~c, Q!.
(3) Add the best k concepts to Q.
Figure 1 shows an example query expanded by local context analysis
The application for the local context analysis:
1. The cross language retrieval
2. The topic segmentation
3. Distribution of IR, choosing the right collections to search for
The experimental conclusion:
2014年2月14日星期五
Evaluation
IIR chapter 8. OR MIR 3
2. Karen Sparck Jones, (2006). What's the value of TREC: is there a gap to jump or a chasm to bridge? ACM SIGIR Forum, Volume 40 Issue 1 June 2006 http://doi.acm.org/10.1145/1147197.1147198
3. Kalervo Järvelin, Jaana Kekäläinen. (2002) Cumulated gain-based evaluation of IR techniques ACM Transactions on Information Systems (TOIS) Volume 20 , Issue 4 (October 2002) Pages: 422 – 446 http://doi.acm.org/10.1145/582415.582418
The TREC Programme has been very successful at generalising. It has shown that essentially simple methods of retrieving documents (standard statistically-based VSM, BM25, InQuery, etc) can give decent ‘basic benchmark’ performance across a range of datasets, including quite large ones. But retrieval contexts vary widely, much more widely than the contexts the TREC datasets embody. The TREC Programme has sought to address variation, but it has done this in a largely ad hoc and unsystematic way. Thus even while allowing for the Programme’s concentration on core retrieval system functionality, namely the ability to retrieve relevant documents, and excluding for now the tasks it has addressed that do not fall under the document retrieval heading, the generalisation the Programme seeks, or is assumed to be seeking, is incomplete. However, rather than simply continuing with the generalisation mission, intended to gain more support for the current findings, it may be time now to address particularisation.
environment and contexts,
The simple historic model for environment variation within this laboratory paradigm was of micro
variation, i.e. of change to the request set - say plain or fancy, or to the relevance criteria and hence set -
say high only or high and partial, for the same set of documents; less commonly there has been change to
the document set while holding request or relevance criteria/practice constant.
Changing all of D, Q and R might seem to imply more than micro variation, or at least could be deemed
to do so if the type of request and/or style of relevance assessment changed, not merely the actual document sets. Such variation, embodying a new form of need as well as new documents to draw on in trying to meet it, might be deemed to constitute macro variation rather than micro variation, and therefore as implicitly enlarging the TREC Programme's reference to contexts.
TREC Strategies:
This TREC failure is hardly surprising. In TREC, as in many other retrieval experiment situations,
there is normally no material access to the encompassing wider context and especially to the actual users,whether because such real working contexts are too remote or because, fundamentally, they do not exist as prior, autonomous realities.
The factors framework refers to Input Factors (IF), Purpose Factors (PF), and Output Factors (OF).
Input Factors and Purpose Factors constrain the set of choices for Output Factors, but for any complex task cannot simply determine them.Under IF for summarising we have properties of the source texts. This includes their Form, Subject type, and Units, which subsume a series of subfactors, as illustrated in Figure 2. It is not di cult to see that such factors apply, in the retrieval case, to documents. They will also apply, in retrieval, to requests, past and current, and to any available past relevant document sets. The particular characterisations of documents and requests may of course be di erent, e.g. documents but not requests might have a complex structure.
retrieval case - the setup with both system and context - o ers.
The non-TREC literature refers to many studies of individual retrieval setups: what they are about,
what they are for, how they seem to be working, how they might be speci cally improved to serve their
purposes better. The generalisation goal that the automated system research community has sought to
achieve has worked against getting too involved in the particularities of any individual setups. My argument here is that, in the light of the generalisation we have achieved, we now need to revisit particularity. That is, to try to work with test data that is tied to an accessible and rich setup, that can be analysed for what it suggests to guide system development as well as for what it o ers for fuller performance assessment. We need to start from the whole setup, not just from the system along with whatever we happen to be able to pull pretty straightforwardly from the setup into our conventional D * Q * R environment model.
Cumulated Gain-Based Evaluation of IR Techniques
Modern large retrieval environments tend to overwhelm their users by their large output. Since all documents are not of equal relevance to their users, highly relevant documents, or document components, should be identified and ranked first for presentation. This is often desirable from the user point of view.In order to develop IR techniques in this direction, it is necessary to develop.
Modern large retrieval environments tend to overwhelm their users by their large output. Since all documents are not of equal relevance to their users, highly relevant documents, or document components, should be identified and ranked first for presentation. This is often desirable from the user point of view. In order to develop IR techniques in this direction, it is necessary to develop.
The second point above stated that the greater the ranked position of a relevant document, the less valuable it is for the user, because the less likely it is that the user will ever examine the document due to time, effort, and cumulated information from documents already seen. This leads to comparison of IR techniques through test queries by their cumulated gain based on document rank with a rank-based discount factor. The greater the rank, the smaller the share of the document score that is added to the cumulated gain.
The normalized recall measure (NR, for short; Rocchio [1966] and Salton and McGill [1983]), the sliding ratio measure (SR, for short; Pollack [1968] and Korfhage [1997]), and the satisfaction—frustration—total measure (SFT, for short; Myaeng and Korfhage [1990] and Korfhage [1997]) all seek to take into account the order in which documents are presented to the user. The NR measure compares the actual performance of an IR technique to the ideal one (when all relevant documents are retrieved first). Basically it measures the area between the ideal and the actual curves. NR does not take the degree of document relevance into account and is highly sensitive to the last relevant document found late in the ranked order.
They first propose the use of each relevance level separately in recall and precision calculation. Thus different P–R curves are drawn for each level. Performance differences at different relevance levels between IR techniques may thus be analyzed. Furthermore, they generalize recall and precision calculation to directly utilize graded document relevance scores.
The nonbinary relevance judgments were obtained by rejudging documents judged relevant by NIST assessors and about 5% of irrelevant documents for each topic. The new judgments were made by six Master’s students of information studies, all of them fluent in English although not native speakers. The
relevant and irrelevant documents were pooled, and the judges did not know the number of documents previously judged relevant or irrelevant in the pool
The proposed measures are based on several parameters: the last rank considered, the gain values to employ, and discounting factors to apply. An experimenter needs to know which parameter values and combinations to use. In practice, the evaluation context and scenario should suggest these values.
2014年2月7日星期五
Probabilistic Information Retrieval and other models
Muddies Point:
1. What are the differences between the bayes model and bayes network models.
2. What will be IR models closing related to other similar methods.
3 What are the disadvantages for choosing the probability models.
The probability models:
The conditional event: P(A, B) = P(A ∩ B) = P(A|B)P(B) = P(B|A)P(A)
From these we can derive Bayes’ Rule for inverting conditional probabilities:
Bayes' Rule:

The 1/0 loss case
In the simplest case of the PRP, there are no retrieval costs or other utility concerns that would differentially weight actions or errors. You lose a point for either returning a nonrelevant document or failing to return a relevant document (such a binary situation where you are evaluated on your accuracy
1/0 LOSS is called 1/0 loss). The goal is to return the best possible results as the top k
documents, for any value of k the user chooses to examine. The PRP then says to simply rank all documents in decreasing order of P(R = 1|d, q). BAYES OPTIMAL a set of retrieval results is to be returned, rather than an ordering, the Bayes
C0 · P(R = 0|d) − C1 · P(R = 1|d) ≤ C0 · P(R = 0|d′) − C1 · P(R = 1|d′)
The Binary Independence Model first present a model which assumes that the user has a single
step information need. As discussed in Chapter 9, seeing a range of results might let the user refine their information need. Fortunately, as mentioned there, it is straightforward to extend the Binary Independence Model so as to provide a framework for relevance feedback, and we present this model in
Since each xt is either 0 or 1, we can separate the terms to give:
O(R|~x,~q) = O(R|~q) · t:xt=1
P(xt = 1|R = 1,~q)
P(xt = 1|R = 0,~q)
t:xt=0
P(xt = 0|R = 1,~q)
P(xt = 0|R = 0,~q)
Adding 1
2 in this way is a simple form of smoothing. For trials with categorical outcomes (such as noting the presence or absence of a term), one way to estimate the probability of an event from data is simply to count the number of times an event occurred divided by the total number of trials.This is referred to as the relative frequency of the event. RELATIVE FREQUENCY Estimating the prob MAXIMUM LIKELIHOOD ability as the relative frequency is the maximum likelihood estimate (or MLE), ESTIMATE MLE because this value makes the observed data maximally likely.
Finite automata and language models
If instead each node has a probability distribution over generating different terms, we have a language model. The notion of a language model is inherently probabilistic. A language model is a function LANGUAGE MODEL that puts a probability measure over strings drawn from some vocabulary. That is, for a language model M over an alphabet S:
Under the unigram language model the order of words is irrelevant, and sosuch models are often called “bag of words” models, as discussed in Chapter 6 (page 117). Even though there is no conditioning on preceding context, this model nevertheless still gives the probability of a particular ordering of
terms. However, any other ordering of this bag of terms will have the same probability. So, really, we have a multinomial distribution MULTINOMIAL over words. So long DISTRIBUTION as we stick to unigram models, the language model name and motivation could be viewed as historical rather than necessary.
1. What are the differences between the bayes model and bayes network models.
2. What will be IR models closing related to other similar methods.
3 What are the disadvantages for choosing the probability models.
The probability models:
The conditional event: P(A, B) = P(A ∩ B) = P(A|B)P(B) = P(B|A)P(A)
From these we can derive Bayes’ Rule for inverting conditional probabilities:
Bayes' Rule:
The 1/0 loss case
In the simplest case of the PRP, there are no retrieval costs or other utility concerns that would differentially weight actions or errors. You lose a point for either returning a nonrelevant document or failing to return a relevant document (such a binary situation where you are evaluated on your accuracy
1/0 LOSS is called 1/0 loss). The goal is to return the best possible results as the top k
documents, for any value of k the user chooses to examine. The PRP then says to simply rank all documents in decreasing order of P(R = 1|d, q). BAYES OPTIMAL a set of retrieval results is to be returned, rather than an ordering, the Bayes
C0 · P(R = 0|d) − C1 · P(R = 1|d) ≤ C0 · P(R = 0|d′) − C1 · P(R = 1|d′)
The Binary Independence Model first present a model which assumes that the user has a single
step information need. As discussed in Chapter 9, seeing a range of results might let the user refine their information need. Fortunately, as mentioned there, it is straightforward to extend the Binary Independence Model so as to provide a framework for relevance feedback, and we present this model in
Since each xt is either 0 or 1, we can separate the terms to give:
O(R|~x,~q) = O(R|~q) · t:xt=1
P(xt = 1|R = 1,~q)
P(xt = 1|R = 0,~q)
t:xt=0
P(xt = 0|R = 1,~q)
P(xt = 0|R = 0,~q)
Adding 1
2 in this way is a simple form of smoothing. For trials with categorical outcomes (such as noting the presence or absence of a term), one way to estimate the probability of an event from data is simply to count the number of times an event occurred divided by the total number of trials.This is referred to as the relative frequency of the event. RELATIVE FREQUENCY Estimating the prob MAXIMUM LIKELIHOOD ability as the relative frequency is the maximum likelihood estimate (or MLE), ESTIMATE MLE because this value makes the observed data maximally likely.
Finite automata and language models
If instead each node has a probability distribution over generating different terms, we have a language model. The notion of a language model is inherently probabilistic. A language model is a function LANGUAGE MODEL that puts a probability measure over strings drawn from some vocabulary. That is, for a language model M over an alphabet S:
Under the unigram language model the order of words is irrelevant, and sosuch models are often called “bag of words” models, as discussed in Chapter 6 (page 117). Even though there is no conditioning on preceding context, this model nevertheless still gives the probability of a particular ordering of
terms. However, any other ordering of this bag of terms will have the same probability. So, really, we have a multinomial distribution MULTINOMIAL over words. So long DISTRIBUTION as we stick to unigram models, the language model name and motivation could be viewed as historical rather than necessary.
2014年1月24日星期五
MIR Section 7.4 and Chapter 8 Notes
Muddy Points:
(1) Searching Method:





- How to evaluate different algorithms in searching the text
- The most common use of the algorithms in text searching
(1) Searching Method:
- Search Sequentially
- Build Data structure to store the data
(2) Main Indexing Technique:
- inverted files
- suffix arrays
- signature files (popular in 1980s)
(3) Regular data structure using in information Retrieval
- sorted arrays
- binary search trees
- B-trees
- Hash table
- Tries
Inverted Files:
- Two elements: Vocabulary and occurrence
- Techniques: Block Addressing
Searching:
- Vocabulary Search
- Retrieval of Occurrence
- Manipulation of Occurrence
- Context inquires are complicated with inverted indices;
Construction:
- Building and maintaining an inverted index is relatively a low cost task
- All the data will be keep in a trie tree data structure
- Merging two indices include merging the sorted vocab
Other Indices for text:
Suffix Trees and Suffix Arrays:
- Suffix Arrays are a space efficient implementation of suffix trees
- Not all the text position needs to be indexed
Structure:
- Suffix Trees are built over all the suffix of the data
- Patricia Tree
Construction in Main Memory:
- concentrate on direct suffix construction
Construction on Suffix Arrays for Large Text:
Signature Files:
Signature Files are word-oriented files based on hashing
Use hash functions to map words
Sequential Searching:
Search on the text that has no data structure to build on
Brute Force Method:
- Trying all possible text patterns
- Examine the Algor with the worst case
KMP Method:
- First linear with worst case behavior
Boyer-Moore Family:
Shift-Or
Suffix Automation:
Piratical Comparison:
Pattern Matching:
Regular Expression:
2014年1月10日星期五
Notes on Information Storage and Retrieval (Chapter 1)
Muddy Points: Can not figure out the Markov Models, and its application in this chapter.
1.1 Definition of the information Retrieval:
IR is concerned with representing, searching, and manipulating large collections of electronic text and other human-language data.

Categories:
Web search:
The machines identifies a set of web pages containing the terms in the query, compute a score for each page, eliminate duplicate and redundant pages, generate summaries of the remaining pages and finally returns summaries and links back to the user for browsing.
Other search application:
Desktop and file system provides other forms of search. Enterprise system once will have the internet search incorporated in the intranet or have their own system of collecting different files.
Other IR Applications:
Document Routing, filtering, and selective dissemination reverse the typical IR process:
Application: The email spam.
Text clustering and categorization systems group documents according to shared properties to the system:
The categorization system stems from the information training the various classes. Which would short unlabeled articles to the same categories.
Summarization systems reduce documents to a few key paragraphs:
Information extraction systems named entities:
Topic detection and tracking systems identify events in streams of news articles:
Questions answering systems:
1.2 Basic Architecture of Information Retrieval System:







1.1 Definition of the information Retrieval:
IR is concerned with representing, searching, and manipulating large collections of electronic text and other human-language data.
History:
First Library Elba Syria 3000 BC
Categories:
Web search:
The machines identifies a set of web pages containing the terms in the query, compute a score for each page, eliminate duplicate and redundant pages, generate summaries of the remaining pages and finally returns summaries and links back to the user for browsing.
Other search application:
Desktop and file system provides other forms of search. Enterprise system once will have the internet search incorporated in the intranet or have their own system of collecting different files.
Other IR Applications:
Document Routing, filtering, and selective dissemination reverse the typical IR process:
Application: The email spam.
Text clustering and categorization systems group documents according to shared properties to the system:
The categorization system stems from the information training the various classes. Which would short unlabeled articles to the same categories.
Summarization systems reduce documents to a few key paragraphs:
Information extraction systems named entities:
Topic detection and tracking systems identify events in streams of news articles:
Questions answering systems:
1.2 Basic Architecture of Information Retrieval System:
Measuring the Systems:
efficiency and effectiveness.
Efficiency can be measured in terms of time and space,
Effectiveness is more dependable on human judgement, but they measure it with relevance: the probability of Ranking principle. This is although a good measurement but neglected the fact that the scope of the information retrieved.
1.3 Working with electronic text:
Text Format:
HTML(HyperText Markup language)
XML(Extensible Markup Language)
The previous two languages are derived from SGML
The Muddy points: Could not understand the tokenization of the language.
After tokenization of the language, we have the big whole sets of the languages and we can also know the frequencies of the languages.
Term Distribution:
The supplements from MBAliib:
齊普夫定律是美國語言學家G.K.齊普夫(George Kingsley Zipf)於本世紀40年代提出的詞頻分佈定律。它可以表述為:如果把一篇較長文章中每個詞出現的頻次統計起來,按照高頻詞在前、低頻詞在後的遞減順序排列,並用自然數個這些詞編上的等級序號,即頻次最高的詞等級為1,頻次次之的等級為2,......,頻次最小的詞等級為D,。若用f表示頻次,r 表示序號,則有fr=C(C為常數)。人們稱該式為齊普夫定律。
齊普夫定律是描述一系列實際現象的特點非常到位的經驗定律之一。它認為,如果我們按照大小或者流行程度給某個大集合中的各項進行排序,集合中第二項的比重大約是第一項的一半,而第三項的比重大約是第一項的三分之一,以此類推。換句話來說,一般來講,排在第k位的項目其比重為第一項的1/k。
齊普夫定律還從定量角度描述了目前流行的一個主題: 長尾巴定律(The Long Tail)。以一個集合中按流行程度排名的物品(如亞馬遜網站上銷售的圖書)為例。表示流行程度的圖表會向下傾斜,位於左上角的是幾十本最流行的圖書。該圖會向右下角逐漸下降,那條長尾巴會列出每年銷量只有一兩本的幾十萬種圖書。換成英文即齊普夫定律最初應用的領域,這條長尾巴就是你很少會遇到的幾十萬個單詞,譬如floriferous或者refulgent。
把流行程度作為大致衡量價值的標準,齊普夫定律隨後就會得出每一個物品的價值。也就是說,假設有100萬個物品,那麼最流行的100個物品將貢獻總價值的三分之一,其次的10000個物品將貢獻另外的三分之一; 剩餘的98.99萬個將貢獻剩下的三分之一。有n個物品的集合其價值與log(n)成正比。
Language Modeling:
Predictions concerning the content of the unseen text made by way of a special kind of probability distribution known as a language model. This simple probability modelization is 1.
we can use this simple model as to predict the unseen play probabilities. This technic is called maximum likelihood estimate.
Higher order models:
we have the conditional probabilities
Markov Models:
Markov Models are finite-state automata augmented with transition probabilities.
马氏链描述一种随机过程,从一时期向下一时期的状态按一定的概率转移。下时期的状态取决于本期的状态,与过去无关。
存在两种链的方式:正则链:从任一状态出发有限次数转移能以正概率达到另一个状态
吸收链:从任一非吸收状态转移到达吸收状态。
TREC Tasks:
Open Source IR Systems:
LUCENE
INDURI
WUMPUS
---------------------------------------------------------------------------------------------------------------
FOA process of readers:
1. Asking a question
2. Constructing an answer
3. Assessing the answer
Working with the IR tradition:
Keywords are linguistic atoms- pieces of words or phrases used to characterize the subject of a document.
Elements of query language:
query language
natural language
domain of discourse
Computer Science is a border term of AI.
The vocabulary size- the total number of keywords
订阅:
博文 (Atom)